AI Application Optimization: Why Vibe-Coded Apps Fail | CodeConductor
Vibe Coding
AI Application Optimization: Why Vibe-Coded Apps Fail
AI application optimization determines whether an AI system scales or collapses under growth. While vibe-coded apps prioritize speed, production-ready AI requires relational database discipline, indexing strategy, query planning, replication, and observability. OpenAI’s use of PostgreSQL highlights a critical truth: scalable AI depends on infrastructure engineering, not just advanced models. Without built-in optimization, performance debt accumulates as traffic increases.
Paul Dhaliwal
Founder & Chief Executive Officer · Updated Jun 10, 2026·17 min read
Why do some AI products scale to millions of users while others fail under modest traffic?
The answer is AI application optimization – how teams design relational data architecture, configure database systems like PostgreSQL, implement indexing strategies, enforce transactional integrity, and engineer horizontal scalability before deployment ever reaches production.
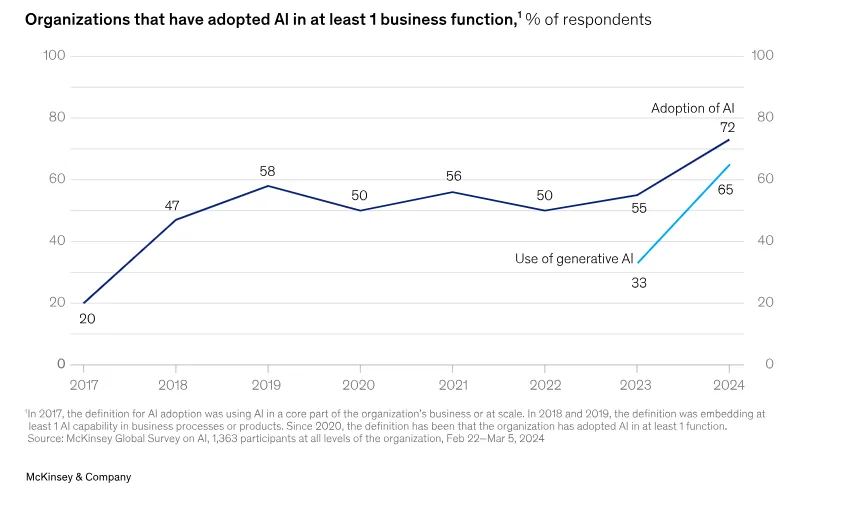
Enterprise AI adoption has accelerated rapidly. According to McKinsey’s 2024 State of AI report, 65% of organizations now use generative AI in at least one business function, nearly double the adoption rate from the previous year (Source).
As AI systems move from experimentation to operational infrastructure, performance bottlenecks shift from model capability to backend reliability, including database performance, replication strategy, query planning, caching layers, and observability.
This shift is visible in infrastructure decisions at the highest level.
A recent InfoQ report confirms that OpenAI runs core ChatGPT workloads on PostgreSQL as part of its infrastructure stack, relying on relational database stability, JSONB storage, mature query optimization, and replication alongside other data systems rather than depending solely on vector databases (Source).
That architectural choice reflects production discipline: Structured schema design, ACID compliance, scaling readiness, and cost-aware engineering.
Yet many AI products are built through rapid “vibe coding”—prioritizing speed, surface functionality, and quick deployment over database engineering, indexing discipline, and scalability planning.
These applications often ignore optimization layers that determine survivability under real-world load.
This is where CodeConductor jumps in, embedding AI application optimization directly into backend generation, integrating relational modeling, index-aware query construction, replication-ready architecture, and infrastructure observability from day one rather than retrofitting performance later.
If OpenAI’s infrastructure signals what production AI requires, the next question becomes clear: why do so many AI builders still ignore these optimization fundamentals?
The Illusion of Vibe Coding
Vibe-coded AI applications prioritize speed and rapid deployment over database engineering, indexing strategy, replication planning, and infrastructure optimization.
While this approach accelerates prototyping, it often ignores the architectural foundations required for scalability, performance stability, and long-term production reliability.
Vibe coding feels productive because it reduces friction. Developers connect a model API, attach a lightweight database, deploy to a cloud platform, and ship features quickly. Early demos work. Small user groups experience minimal latency. The system appears stable.
The problem is not functionality. The problem is architecture.
Vibe-coded systems typically:
Default to unmanaged or minimally configured databases
Store semi-structured data without index planning
Avoid schema normalization
Skip replication and failover configuration
Launch without observability or performance monitoring
These decisions reduce development time in the short term. They increase performance risk in the long term.
Why Optimization Gets Ignored?
Optimization is often deferred because:
Early traffic volume is low
The infrastructure cost appears minimal
Query performance seems acceptable
Scaling requirements feel distant
However, infrastructure debt compounds faster than feature debt.
When user growth increases:
Query latency rises
CPU utilization spikes
Lock contention appears
Database bottlenecks surface
Cloud costs escalate unpredictably
These failures do not originate in the AI model. They originate from missing optimization layers.
The Psychological Trap
Rapid AI builders optimize for visible progress:
UI responsiveness
Model output quality
Feature iteration speed
Production systems optimize for invisible stability:
Transaction isolation
Index efficiency
Replication topology
Failure recovery
Cost control under load
The difference is architectural foresight.
What OpenAI’s Infrastructure Signals
When organizations operating at a global scale choose relational discipline, query planning maturity, and replication readiness, it signals that optimization is not optional. It is foundational.
Vibe-coded applications assume scaling can be added later. Production AI systems assume scaling must be engineered before traffic arrives.
That distinction defines survivability.
This leads to the next critical layer:
If serious AI systems prioritize infrastructure discipline, what specific architectural decisions separate them from rapidly built applications?
OpenAI’s PostgreSQL Decision – What It Signals About Production AI?
According to InfoQ, OpenAI uses PostgreSQL as a primary relational store within ChatGPT’s broader infrastructure stack, supporting critical workloads at massive scale. This signals that production AI systems rely on relational databases, structured schema design, JSONB support, query optimization, and replication readiness alongside other technologies to maintain performance and reliability at scale.
OpenAI’s decision to anchor key ChatGPT workloads on PostgreSQL signals infrastructure discipline rather than rapid experimentation, emphasizing structured schema design, transactional integrity, and predictable scaling.
PostgreSQL is a mature relational database known for transactional integrity, extensible indexing, and performance tuning capabilities.
The InfoQ report highlights that OpenAI leverages PostgreSQL features such as relational consistency and JSONB support to manage application workloads (Source). PostgreSQL provides:
These features are associated with long-term production stability, not short-term prototyping convenience.
What This Decision Signals About Production AI
Despite the growing popularity of vector databases for embedding storage and semantic retrieval, OpenAI maintains relational infrastructure as part of its architectural foundation.
That signals several principles:
AI systems manage structured and transactional data in addition to embeddings.
Data integrity must remain consistent under concurrent access.
Query performance must remain predictable as datasets grow.
Scaling strategies require deliberate engineering rather than reactive upgrades.
Relational databases address these requirements through constraint enforcement, query optimization, and replication capabilities.
Why Vibe-Coded Applications Overlook This Layer?
Rapid AI builders often prioritize immediate functionality over infrastructure planning. Common patterns include:
Default database configurations without performance tuning
Minimal schema enforcement
Delayed indexing strategy
Single-instance deployments without redundancy
These shortcuts reduce development friction early. However, they increase fragility as traffic grows.
When concurrency increases:
Unindexed queries slow significantly
Schema inconsistencies surface
Single-node bottlenecks limit throughput
Failover gaps increase downtime risk
The absence of relational discipline compounds over time.
Architectural Contrast
Infrastructure Principle
Production-Engineered AI
Vibe-Coded AI
Database Usage
Mature relational systems are integrated intentionally
Convenience-first configuration
Data Integrity
Enforced through constraints and transactions
Loosely structured
Query Planning
Analyzed and optimized
Default execution paths
Replication
Designed for availability
Added reactively
Scaling Strategy
Engineered before traffic growth
Considered after performance issues
The difference is not model capability. It is architectural maturity.
If relational discipline forms the backbone of production AI systems, the next question becomes more granular:
Which optimization layers inside relational systems actually determine scalability and performance predictability?
Relational Discipline – Why PostgreSQL Still Powers Serious AI Systems
Relational discipline ensures data integrity, transactional consistency, and predictable system behavior in production AI systems.
PostgreSQL remains foundational because it enforces structured schema design, manages concurrent transactions safely, and maintains reliable state transitions under load.
Basically, the relational discipline is not about legacy preference. It is about structural control.
Production AI systems handle far more than model inference. They manage user identities, billing records, permissions, audit logs, configuration states, feedback data, and operational metadata alongside embeddings and generated outputs. These workloads require:
Explicit relationships between entities
Constraint enforcement at the database level
Controlled concurrency handling
Safe state transitions during updates
Without structural enforcement, system behavior becomes unpredictable as complexity increases.
What Relational Discipline Actually Means
Relational discipline begins with deliberate data modeling.
It includes:
Schema-defined architecture
Clearly typed columns
Defined relationships between tables
Structured data boundaries
Database-level constraints
Primary and foreign key enforcement
Uniqueness guarantees
Referential integrity protection
Transaction isolation
Atomic updates
Consistent read/write behavior
Protection against race conditions
These mechanisms ensure that growth in traffic or data volume does not introduce silent corruption or an inconsistent state.
Structure prevents instability before scale magnifies it.
Maintain a consistent state during simultaneous requests
Protect data integrity through enforced relationships
Provide deterministic outcomes during complex updates
These properties matter most when user activity scales.
Where Vibe-Coded Applications Deviate?
Vibe-coded systems often treat the database as flexible storage rather than as an enforcement layer. Common shortcuts include:
Allowing schema drift without normalization
Handling relational logic exclusively in application code
Ignoring transaction isolation planning
Deferring integrity validation
At low traffic, these shortcuts appear harmless. Under concurrency, they introduce:
Duplicate records
Partial state updates
Broken entity relationships
Increasing query complexity
The absence of relational discipline converts early development speed into long-term fragility.
Integrity & Structural Comparison
Structural Principle
Relational-Engineered System
Vibe-Coded System
Data Relationships
Enforced in the database schema
Managed inconsistently in code
Constraints
Guaranteed at the storage layer
Optional or delayed
Transaction Safety
Controlled under concurrency
Vulnerable to race conditions
State Consistency
Deterministic
Prone to edge-case failures
Get insights in your inbox!!
Weekly tips on building smarter apps. Join 8,200+ founders and builders.
No spam. Unsubscribe anytime. We respect your privacy.
Relational discipline protects systems before scale exposes architectural weaknesses.
Structure establishes integrity. However, integrity alone does not ensure speed.
The next performance layer determines how efficiently structured and semi-structured data is retrieved, filtered, and indexed under real-world traffic:
Indexing and query optimization.
SONB & Indexing – The Optimization Layer Most AI Builders Skip
JSONB and indexing strategies determine how efficiently semi-structured and relational data are retrieved in production AI systems. Proper indexing reduces query latency, prevents full-table scans, and maintains performance predictability as datasets grow.
Moreover, modern AI systems rarely operate on purely rigid schemas. They manage dynamic metadata, feature flags, model configurations, user preferences, and contextual attributes that evolve. PostgreSQL’s JSONB data type enables semi-structured storage while retaining queryability.
However, storing flexible data is not the same as optimizing it.
What JSONB Enables in AI Systems?
JSONB allows structured storage of evolving attributes without abandoning relational discipline. It supports:
Nested key-value structures
Efficient binary storage format
Queryable fields inside JSON documents
Compatibility with relational joins
This flexibility makes it suitable for AI workloads where metadata evolves frequently.
But flexibility without indexing creates performance risk.
Indexes reduce the number of rows scanned during query execution. Without indexing, the database must inspect large portions of a table, increasing CPU load and latency.
Query Planning & Execution — Where Performance Is Won
Query planning determines how a database executes a request by selecting the most efficient execution path. Proper query analysis reduces latency, lowers resource usage, and maintains performance stability under concurrent load.”
Indexes reduce lookup cost. Query planning determines how those indexes are used.
When a query runs, the database:
Estimates matching row counts
Selects join strategies
Determines index usage
Calculates execution cost
If queries are poorly structured or statistics are inaccurate, inefficient execution paths are chosen.
Tools That Expose Query Behavior
PostgreSQL provides built-in diagnostics:
EXPLAIN → Displays the planned execution strategy.
EXPLAIN ANALYZE → Executes the query and shows actual runtime behavior, comparing estimates with real execution.
Without inspecting execution plans, inefficiencies remain invisible until traffic increases.
Common Performance Pitfalls
Filtering on non-indexed columns
Inefficient JOIN conditions
Over-fetching unnecessary columns
Repeated identical queries
Under concurrency, small inefficiencies multiply.
Execution Impact Comparison
Execution Behavior
Optimized Query
Unoptimized Query
Index Usage
Targeted
Ignored
Join Strategy
Cost-based
Inefficient
Resource Use
Controlled
Escalating
Latency Stability
Predictable
Variable
Query efficiency determines cost per request and response stability.
As traffic grows, execution cost compounds. The next layer determines how the workload is distributed across the infrastructure to prevent bottlenecks:
Replication and horizontal scaling.
Replication & Horizontal Scaling — Engineered for Load
Replication and horizontal scaling distribute database workload across multiple nodes to improve availability, reduce latency, and prevent bottlenecks. These strategies ensure production AI systems remain stable under increasing traffic and concurrent demand.
Efficient queries reduce cost per request. Scaling architecture determines how the system behaves when the request volume multiplies.
As AI applications grow, user traffic, background processing, API integrations, and data updates occur simultaneously. A single database instance becomes a bottleneck when:
Read traffic overwhelms CPU resources
Write operations increase lock contention
Geographic users experience high latency
Failures create downtime without redundancy
Scaling must be engineered before these conditions appear.
Replication: Distributing Read Workloads
Replication creates copies of the primary database to handle read-heavy traffic.
Workload distribution preserves stability during demand surges.
Why This Layer Is Often Deferred
Rapid AI deployments are frequently:
Rely on default single-instance configurations
Add replicas only after performance incidents
Treat scaling as a cloud setting rather than an architectural decision
Scaling is not a toggle. It is a design principle.
As traffic expands, the next challenge is not just distributing workload — it is understanding system behavior in real time.
That requires:
Observability and performance monitoring.
Observability — The Visibility Layer Most AI Builders Ignore
Observability enables AI systems to monitor query latency, resource usage, error rates, and system behavior in real time. Without monitoring, performance bottlenecks remain undetected until failures impact users.
Scaling distributes workload. Observability explains system behavior under that workload.
Production AI systems require visibility into:
Query latency
CPU and memory utilization
Lock contention
Error rates
Throughput trends
Without these signals, teams react to incidents instead of preventing them.
What Observability Provides
Effective monitoring allows teams to:
Detect performance degradation early
Identify inefficient queries
Trace request bottlenecks
Measure scaling effectiveness
Prevent cascading failures
Visibility converts infrastructure from guesswork into measurable control.
What Happens Without It
Systems launched without observability often experience:
Undiagnosed latency spikes
Delayed failure detection
Increased downtime during incidents
Reactive troubleshooting under pressure
Once visibility is established, one final architectural question remains:
How do relational systems coexist with vector databases in modern AI stacks?
Hybrid Architecture – Why Vector Databases Are Not Enough
Hybrid architecture combines relational databases with vector databases to support both structured transactions and semantic search. Relational systems manage consistency and business logic, while vector systems power embedding retrieval. Production AI requires both layers to operate efficiently at scale.
Modern AI systems handle two fundamentally different workloads:
Structured operational data (users, billing, permissions, logs)
High-dimensional embeddings for semantic retrieval
These workloads have different performance characteristics and storage requirements.
A single database model cannot efficiently optimize both.
What Happens Without a Hybrid Strategy
Applications that rely exclusively on:
Relational systems may struggle with high-speed embedding retrieval.
Vector-only systems may lack transactional integrity and structured enforcement.
Balanced architecture prevents performance trade-offs from becoming systemic weaknesses.
Hybrid infrastructure addresses storage specialization. One final strategic gap remains:
Even when architecture is technically sound, many AI builders fail to integrate these optimization layers holistically from the start.
The next section will address that gap.
The Optimization Gap – Why Most AI Apps Never Reach Production Stability
Most AI applications fail to reach production stability because optimization is treated as a post-launch task instead of a foundational design principle. Without structured data modeling, indexing strategy, query planning, replication, scaling, and observability integrated from the start, performance debt compounds as usage grows.
Every layer discussed — relational modeling, JSONB indexing, query planning, replication, horizontal scaling, observability, and hybrid architecture — forms part of a cohesive system.
The failure rarely happens at the model layer.
It happens when these optimization layers are:
Added reactively
Implemented partially
Misaligned across the stack
Deferred until traffic increases
Optimization debt compounds quietly.
How Optimization Debt Accumulates
When systems are launched without an integrated infrastructure discipline:
The schema evolves inconsistently
Indexes are added reactively
Queries are optimized after complaints
Replication is introduced after outages
Monitoring begins after failures
Each reactive decision increases architectural complexity.
The result is:
Rising latency variance
Escalating infrastructure costs
Operational fragility
Increasing maintenance overhead
Growth amplifies weaknesses.
OpenAI’s infrastructure decisions signal that scalable AI requires disciplined architecture — relational enforcement, indexing strategy, execution analysis, replication, workload distribution, and visibility.
Optimization is not a feature. It is a structural property of the system.
How CodeConductor Embeds AI Application Optimization From Day One?
CodeConductor embeds AI application optimization into backend architecture by integrating structured data modeling, index-aware query generation, replication-ready deployment patterns, scaling strategies, and observability from the outset.
Optimization is built into system design rather than added after performance issues emerge.
The architectural layers discussed throughout this article—relational discipline, JSONB indexing, query planning, replication, horizontal scaling, observability, and hybrid database strategy- only deliver value when implemented cohesively.
Many AI systems fail not because these components are unavailable, but because they are assembled reactively.
Production stability requires integration, not patchwork.
What Integrated Optimization Looks Like?
Embedding optimization from the start means:
Designing schema structures intentionally
Planning indexing based on query patterns
Evaluating execution cost before scale
Configuring replication as part of deployment
Monitoring performance from launch
Aligning relational and vector workloads appropriately
These elements must function as a coordinated system.
When optimization is deferred, each adjustment introduces new complexity. When it is foundational, scaling remains controlled.
Architectural Cohesion vs Reactive Engineering
System Approach
Integrated Optimization
Reactive Adjustments
Schema Planning
Designed intentionally
Refactored repeatedly
Indexing
Query-aware
Added after the slowdown
Execution Analysis
Proactive
Incident-driven
Scaling
Structured deployment
Emergency expansion
Monitoring
Enabled from launch
Activated after the outage
Integrated systems maintain predictable growth trajectories.
Where CodeConductor Aligns
CodeConductor is built around AI application optimization as a structural principle.
Instead of generating rapid prototypes that require backend refactoring later, the platform integrates:
Relational modeling discipline
Index-aware backend generation
Replication-conscious deployment patterns
Scalable infrastructure design
Observability-ready architecture
Optimization becomes a property of the system itself — not a corrective measure applied after traffic exposes weaknesses.
If you’re building AI products meant to survive beyond the prototype phase, infrastructure discipline cannot be optional.
Try CodeConductor for free for a limited time and experience what production-ready AI architecture looks like when optimization is built in from day one.
Ready to Build Without Code?
See how CodeConductor helps enterprises ship faster while staying compliant.
Paul Dhaliwal is a tech innovator and Founder of CodeConductor, an open-source no/low-code platform. With 10+ years of experience in AI and scalable development, Paul focuses on crafting intelligent solutions that drive real-world value. A firm believer in the mantra "Eat, Sleep, Code, Repeat," he balances his passion for software with a love for travel and family.
⚡
Build your app
No coding. No designers. Just describe what you want and watch AI build it.